It's been a while since I posted and I'm going to write a quick one, every consultant is going to be asked at some point in any project to mask the client's data for testing purposes etc. and as I'm sure you know there is no out of the box functionality to do this, only workarounds like:
1. Apply a certain percentage on the whole data base, for example multiply by 0.45656 , but the drawback here that if you know any of the real figures before masking, you can figure out the actual numbers by working out the multiplier.
2. Apply a certain percentage on part of the data base (For example expense accounts 0.56 , revenue 0.434...) and this is of course better than the first method, but if the client wants more complex logic then this will not work.
3. Write a Java CDF that looks like this:
 compile the project, get the .jar files, and follow the CDF registration as specified by Oracle documentation. then you can call that CDF in your calc script (@Random()).
compile the project, get the .jar files, and follow the CDF registration as specified by Oracle documentation. then you can call that CDF in your calc script (@Random()).
4. Write a Groovy CDF using the new Calculation Manager CDF @CalcMgrGroovyNumer, thanks to Celvin's excellent article in Oracle community forums, we actually know how to use the new Groovy CDFs.
I remember two years back in an Oracle client event in Dubai, the Oracle EPM US team (Marc Seewald specifically) mentioned Groovy and its pivotal role in the product road map, I remember asking Marc what is the alternative to Java CDF in PBCS and he simply said "Groovy", at that time it was not clear to me, but after seeing the two new functions, it is starting to make sense.
So lets get on with it, first I want to make sure my Groovy script is actually working, I use the Groovy console, simple and easy to install. as you can see below the function is working and returning random numbers.

And this is my form with the data I want to mask:

I'm using the same value (100) to highlight the different results and make sure we are getting the data masked 100%.
Now my calculation script:

Its a simple function, not passing any parameters just returning a random double, and using it to mask my data. after executing this script I'll get the following results:

Looking at my masked data here, you can easily work out the Dense/Sparse configuration in my outline. what you see above is a random double for every block (hence Sydney has 64.1346... across all dense members).
To fix this, we can either change the Groovy function logic or use @CalcMode(Cell) setting in the script as follows:

I just added


1. Apply a certain percentage on the whole data base, for example multiply by 0.45656 , but the drawback here that if you know any of the real figures before masking, you can figure out the actual numbers by working out the multiplier.
2. Apply a certain percentage on part of the data base (For example expense accounts 0.56 , revenue 0.434...) and this is of course better than the first method, but if the client wants more complex logic then this will not work.
3. Write a Java CDF that looks like this:

4. Write a Groovy CDF using the new Calculation Manager CDF @CalcMgrGroovyNumer, thanks to Celvin's excellent article in Oracle community forums, we actually know how to use the new Groovy CDFs.
I remember two years back in an Oracle client event in Dubai, the Oracle EPM US team (Marc Seewald specifically) mentioned Groovy and its pivotal role in the product road map, I remember asking Marc what is the alternative to Java CDF in PBCS and he simply said "Groovy", at that time it was not clear to me, but after seeing the two new functions, it is starting to make sense.
So lets get on with it, first I want to make sure my Groovy script is actually working, I use the Groovy console, simple and easy to install. as you can see below the function is working and returning random numbers.

And this is my form with the data I want to mask:

I'm using the same value (100) to highlight the different results and make sure we are getting the data masked 100%.
Now my calculation script:

Its a simple function, not passing any parameters just returning a random double, and using it to mask my data. after executing this script I'll get the following results:

Looking at my masked data here, you can easily work out the Dense/Sparse configuration in my outline. what you see above is a random double for every block (hence Sydney has 64.1346... across all dense members).
To fix this, we can either change the Groovy function logic or use @CalcMode(Cell) setting in the script as follows:

I just added
So now lets try with the new setting (I resetted the values to 100) and ran the script again.
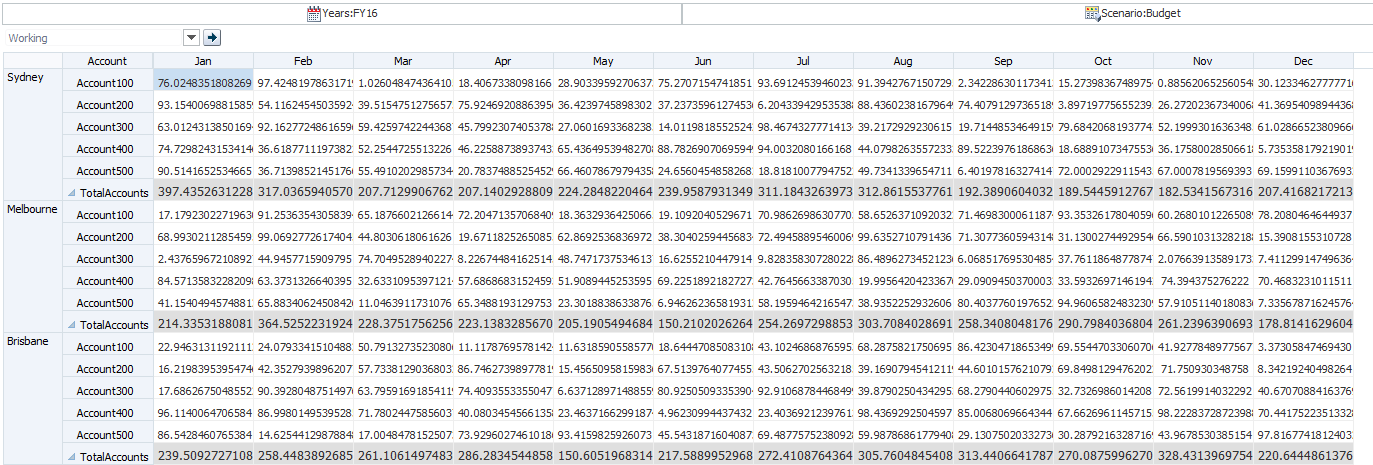
Voila! data is masked and looking meaningless, and no similarities whatsoever.
Happy New Year :)
May the Cosmos be with you!