In this post, we will try to understand the difference in the way Hyperion Planning (Essbase to be specific) and TM1 structure and deal with data. In Hyperion Planning when you create your Application, and once you have finalized your dimensions (apart from the standard dimensions), next thing you need to do is define density/sparsity of the dimensions.

So TM1 folks can grasp the difference between their definition of density/sparsity and Hyperion's, the number of stored members in dense dimensions will give us our Essbase block size, and the number of stored members in our sparse dimensions will give us the number of potential Essbase blocks (this is the first thing you learn in Essbase, I call it baptism of Hyperion professionals). In my Demo application, I kept the settings created by default. I will show next my Demo application outline, I have added few members to use in this post.

So if we do the calculation explained above, we will get our block size and the potential number of blocks. In this post, I want to highlight a key difference in Hyperion Planning and TM1, the level at which we store data (level zero or upper levels). So in order to get on with this, I need to show the two version members/elements I created in my Version dimension.


As shown above, we have two types of versions we can create in Planning:














So TM1 folks can grasp the difference between their definition of density/sparsity and Hyperion's, the number of stored members in dense dimensions will give us our Essbase block size, and the number of stored members in our sparse dimensions will give us the number of potential Essbase blocks (this is the first thing you learn in Essbase, I call it baptism of Hyperion professionals). In my Demo application, I kept the settings created by default. I will show next my Demo application outline, I have added few members to use in this post.

So if we do the calculation explained above, we will get our block size and the potential number of blocks. In this post, I want to highlight a key difference in Hyperion Planning and TM1, the level at which we store data (level zero or upper levels). So in order to get on with this, I need to show the two version members/elements I created in my Version dimension.

As shown above, we have two types of versions we can create in Planning:
- Standard Bottom Up
- Standard Target
The key difference is our ability to store data in upper-level blocks (i.e parent members). It is pretty straightforward, in bottom-up versions you cannot but enter data in level zero members, whereas in target versions there are no restrictions.
Ok, now I want to create a simple data form as shown below, see the main difference in the editable cells, the column I'musing the bottom up version with has only one editable cell, whereas the column with target version has 3 editable cells.
Before I enter and save any data, I want to look at my application stats.

Number of existing blocks: 0
Existing level 0 blocks: 0
Existing upper-level blocks:0
Now let us enter some data in the bottom-up version.
And our stats will look like:
Number of existing blocks: 1
Existing level 0 blocks: 1
Existing upper-level blocks:0
Moving on to the target version, I will enter data in the level zero member.
And our stats will look like:
Number of existing blocks: 2
Existing level 0 blocks: 2
Existing upper-level blocks:0
Ok now before I enter data in parent members, I want to clear the data in level zero blocks, and clear missing blocks to reset application stats.
And our stats will look like:
Number of existing blocks: 2
Existing level 0 blocks: 0
Existing upper-level blocks:2
Cognos TM1
I went and fixed my dimensions to replicate almost the same structure we followed in our Hyperion Planning Demo application.
I want to create a cube now.

Since I only need at least two dimensions in my TM1 cube, I selected only Version, Entity, and Account. Unlike Hyperion Planning's Essbase we don't tag the dimensions and specify if they are dense or sparse, what we do is order the dimensions in the cube from smallest sparse to largest sparse, followed by smallest dense to largest dense, that is one way or ordering dimensions, there is no right or wrong since everything depends on your data and everything can simply change.
Now because TM1 is an in-memory OLAP engine, meaning everything is kept in the memory (the whole cube), and there is no concept of retrieving blocks from harddesk to the memory, you specify your sparse and dense dimensions order so that you can optimize your cube size and performance.
Ok now let us create a view.

We have only 3 editable cells (only the level zero elements), in subsequent posts, I will explain element types and differences between Planning and TM1. But for now, I will enter some data in my view.
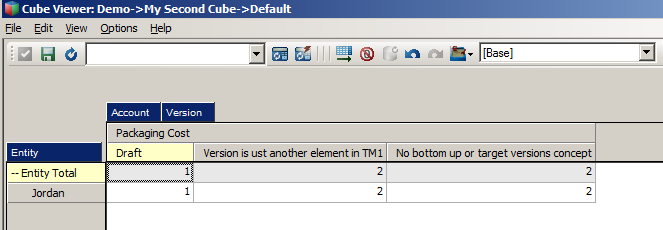
And our stats will look like.

TM1 is all about RAM memory, and our stats reflect the same, memory usage per cube and dimension, playing around with your ordering and loading the data again is the equivalent of outline restructuring in Hyperion Planning in order to optimize application performance.
Now I would like to conclude but I prefer to do so in a simple way so that people from the non-IT background can understand what is happening. The key difference between Hyperion Planning's Essbase and TM1 is the way data is stored, in Hyperion Planning's Essbase you have a store room with n number of boxes (sparse dimensions) of the same size(dense dimensions), when you need a specific box(s) you refer to your inventory list (Essbase index and page files) and you go and fetch them out of the store room (from harddesk to memory), bring them to your office, and check them out.
Whereas in TM1 you have a number big boxes in the same room you are sitting in (memory) , every box has a number of smaller boxes varying in sizes (cubes), and you have your labels on the boxes so you can easily go and fetch whatever you need. and at the end of the day when you want to leave the room, you move your boxes to the store room (from memory to harddesk), and next day when you come back to the room, you bring the boxes with you and keep them in the room the whole day until you are about to leave.
Until we meet again, may the Cosmos be with you.
This comment has been removed by the author.
ReplyDeleteHi Omar, Please guide how the block size and potential number of blocks is calculated here (referring to 3rd diagram). Thanks.
ReplyDeleteHi Priyanka,
DeleteSorry for the very late reply, I was moving countries/jobs recently and been very busy.
Block size is the multiplication of your dense stored members , potential number of blocks is the multiplication of your stored sparse members.
Omar
Nice post .Keep updating Cognos TM1 online training Bangalore
ReplyDeleteNicepost.
ReplyDeleteKeep updating more Blogs.
cognos tm1 training
cognos tm1 online training
cognos tm1 certification training